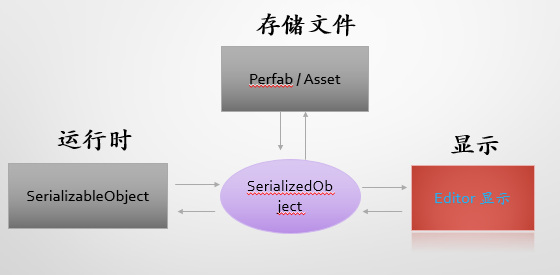
目标
项目中为了减少打包后的包体大小,针对 IL2CPP 的打包方案做包体缩小的优化
问题
IL2CPP 虽然在性能上比 mono 有优势,但是当代码量增多时,包体会增大
研究
2015 年的一篇帖子有提到 IL2CPP 在打包时会将未使用的属性打包进 IL 中,作者测评下来发现修改裁剪工具,剔除不需要的属性能减少 6% 的 IL2Cpp 大小。
原帖地址
在 unity2017 版本中,并没有作者所提到的 UnusedByteCodeStripper2.exe 工具,推测 unity 可能在后续版本更新中做了优化。
测试 Attribute 的优化
新建空的项目工程,创建 test.cs , 对其中的 test 字段使用属性元数据。 选择 IL2Cpp 打包方案打包 apk 包,使用 IL2Cppdumper ,反编译查看包体中的 libil2cpp.so , 对比查看使用了属性以及未使用属性的打包结果。
目标
项目中为了减少打包后的包体大小,针对 IL2CPP 的打包方案做包体缩小的优化
问题
IL2CPP 虽然在性能上比 mono 有优势,但是当代码量增多时,包体会增大
研究
2015 年的一篇帖子有提到 IL2CPP 在打包时会将未使用的属性打包进 IL 中,作者测评下来发现修改裁剪工具,剔除不需要的属性能减少 6% 的 IL2Cpp 大小。
原帖地址
在 unity2017 版本中,并没有作者所提到的 UnusedByteCodeStripper2.exe 工具,推测 unity 可能在后续版本更新中做了优化。
测试 Attribute 的优化
新建空的项目工程,创建 test.cs , 对其中的 test 字段使用属性元数据。 选择 IL2Cpp 打包方案打包 apk 包,使用 IL2Cppdumper ,反编译查看包体中的 libil2cpp.so , 对比查看使用了属性以及未使用属性的打包结果。
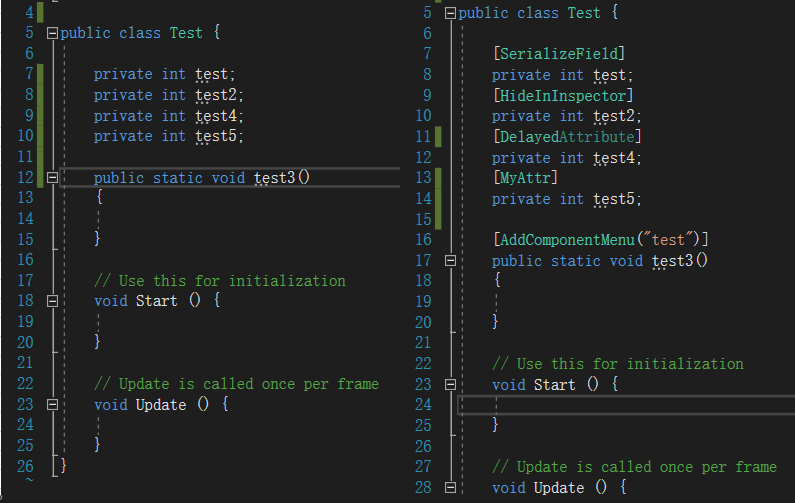
未使用属性的 attribute 在反编译结果中未找到对应的声明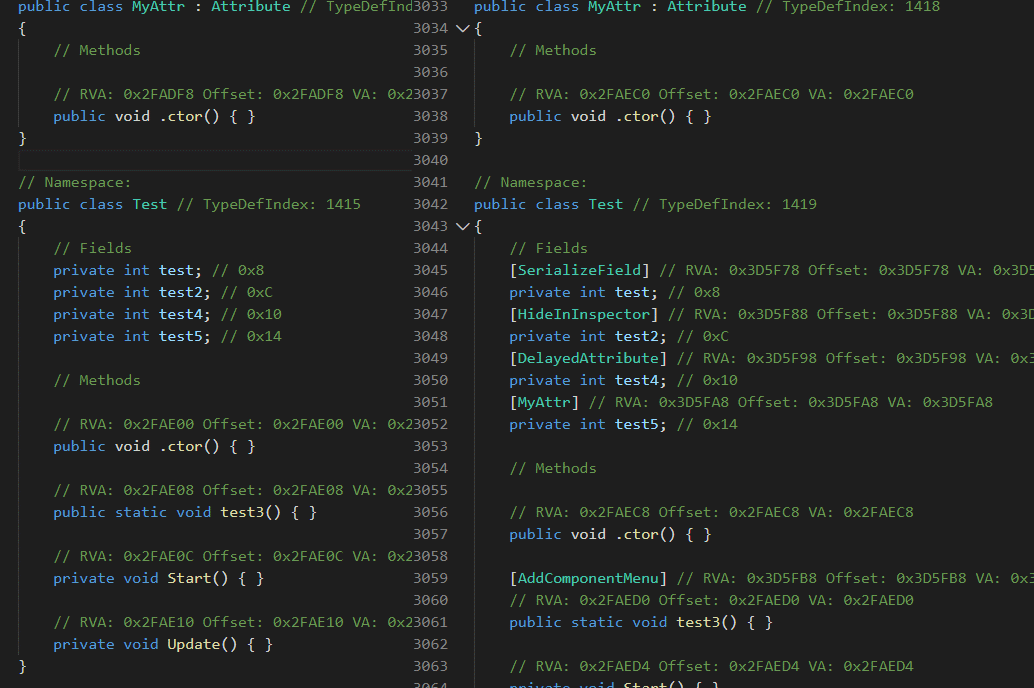
Managed bytecode stripping with IL2CPP
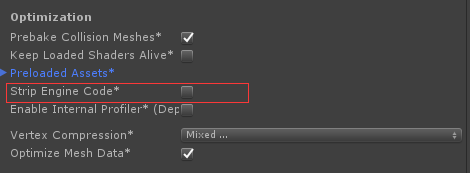
查找文档发现 unity2017 已经新增了对 IL 代码的裁剪选项,此选项开启后会使用 UnityLinker(is a version of the Mono IL Linker) 对引擎中未引用的代码进行剔除。
剔除工作是基于代码的静态分析,需要注意以下情况,并处理。
- 如果代码中使用了反射来引用,可能会出现运行时引用类型被剔除的报错。
- 项目打包中会有 prefab 资源的提前构建 ab 包,此构建过程在 UnityLinker 调用之前执行,一些类型的引用只存在与 Prefab 中,也会出现类型丢失问题。需要手动排查并引用进 mono 防止类型被剔除。
执行
对裁剪后的包进行冒烟测试,查找并修复类型丢失的问题。
运行时,unity 会抛出类型丢失的错误,并附带一个应用 ID, 通过 ClassIDRefrence 查找,获知对应的类型。
反射引用
测试下来并未出现有相关类型报错的问题,说明代码中没有通过这种方法对类型进行引用。
资源 ab 包
出现一些 Prefab 引用类型丢失的情况,新增 link.xml 放置在 Assets 下,指导 UnityLinker 的剔除保留。1
2
3
4
5
6
7
8
9
10
11
12
13
<linker>
<assembly fullname="System">
<type fullname="System.ComponentModel.TypeConverter" preserve="all" />
</assembly>
<assembly fullname="mscorlib">
<namespace fullname="System.Security.Cryptography" preserve="all"/>
</assembly>
<assembly fullname="UnityEngine">
<type fullname="UnityEngine.Flare" preserve="all"/>
<type fullname="UnityEngine.Avatar" preserve="all"/>
</assembly>
</linker>
结果
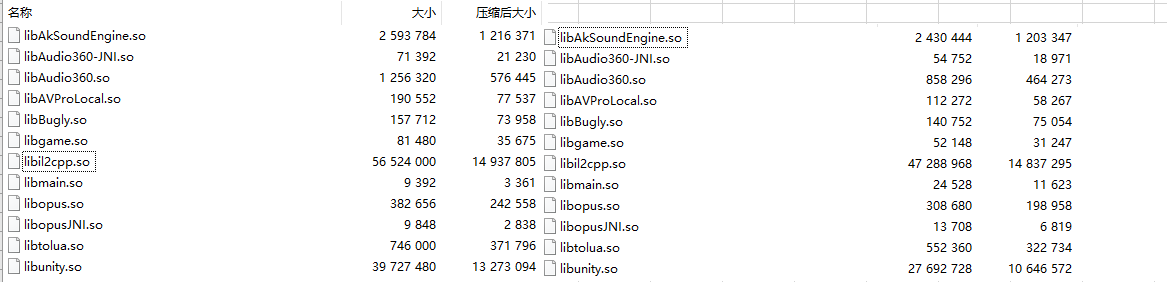
最终包体缩小 34MB

未使用属性的 attribute 在反编译结果中未找到对应的声明
目标
项目中为了减少打包后的包体大小,针对 IL2CPP 的打包方案做包体缩小的优化
问题
IL2CPP 虽然在性能上比 mono 有优势,但是当代码量增多时,包体会增大
研究
2015 年的一篇帖子有提到 IL2CPP 在打包时会将未使用的属性打包进 IL 中,作者测评下来发现修改裁剪工具,剔除不需要的属性能减少 6% 的 IL2Cpp 大小。
原帖地址
在 unity2017 版本中,并没有作者所提到的 UnusedByteCodeStripper2.exe 工具,推测 unity 可能在后续版本更新中做了优化。
测试 Attribute 的优化
新建空的项目工程,创建 test.cs , 对其中的 test 字段使用属性元数据。 选择 IL2Cpp 打包方案打包 apk 包,使用 IL2Cppdumper ,反编译查看包体中的 libil2cpp.so , 对比查看使用了属性以及未使用属性的打包结果。
未使用属性的 attribute 在反编译结果中未找到对应的声明
Managed bytecode stripping with IL2CPP
查找文档发现 unity2017 已经新增了对 IL 代码的裁剪选项,此选项开启后会使用 UnityLinker(is a version of the Mono IL Linker) 对引擎中未引用的代码进行剔除。
剔除工作是基于代码的静态分析,需要注意以下情况,并处理。
- 如果代码中使用了反射来引用,可能会出现运行时引用类型被剔除的报错。
- 项目打包中会有 prefab 资源的提前构建 ab 包,此构建过程在 UnityLinker 调用之前执行,一些类型的引用只存在与 Prefab 中,也会出现类型丢失问题。需要手动排查并引用进 mono 防止类型被剔除。
执行
对裁剪后的包进行冒烟测试,查找并修复类型丢失的问题。
运行时,unity 会抛出类型丢失的错误,并附带一个应用 ID, 通过 ClassIDRefrence 查找,获知对应的类型。
反射引用
测试下来并未出现有相关类型报错的问题,说明代码中没有通过这种方法对类型进行引用。
资源 ab 包
出现一些 Prefab 引用类型丢失的情况,新增 link.xml 放置在 Assets 下,指导 UnityLinker 的剔除保留。1
2
3
4
5
6
7
8
9
10
11
12
13
<linker>
<assembly fullname="System">
<type fullname="System.ComponentModel.TypeConverter" preserve="all" />
</assembly>
<assembly fullname="mscorlib">
<namespace fullname="System.Security.Cryptography" preserve="all"/>
</assembly>
<assembly fullname="UnityEngine">
<type fullname="UnityEngine.Flare" preserve="all"/>
<type fullname="UnityEngine.Avatar" preserve="all"/>
</assembly>
</linker>
结果
最终包体缩小 34MB
Managed bytecode stripping with IL2CPP
目标
项目中为了减少打包后的包体大小,针对 IL2CPP 的打包方案做包体缩小的优化
问题
IL2CPP 虽然在性能上比 mono 有优势,但是当代码量增多时,包体会增大
研究
2015 年的一篇帖子有提到 IL2CPP 在打包时会将未使用的属性打包进 IL 中,作者测评下来发现修改裁剪工具,剔除不需要的属性能减少 6% 的 IL2Cpp 大小。
原帖地址
在 unity2017 版本中,并没有作者所提到的 UnusedByteCodeStripper2.exe 工具,推测 unity 可能在后续版本更新中做了优化。
测试 Attribute 的优化
新建空的项目工程,创建 test.cs , 对其中的 test 字段使用属性元数据。 选择 IL2Cpp 打包方案打包 apk 包,使用 IL2Cppdumper ,反编译查看包体中的 libil2cpp.so , 对比查看使用了属性以及未使用属性的打包结果。
未使用属性的 attribute 在反编译结果中未找到对应的声明
Managed bytecode stripping with IL2CPP
查找文档发现 unity2017 已经新增了对 IL 代码的裁剪选项,此选项开启后会使用 UnityLinker(is a version of the Mono IL Linker) 对引擎中未引用的代码进行剔除。
剔除工作是基于代码的静态分析,需要注意以下情况,并处理。
- 如果代码中使用了反射来引用,可能会出现运行时引用类型被剔除的报错。
- 项目打包中会有 prefab 资源的提前构建 ab 包,此构建过程在 UnityLinker 调用之前执行,一些类型的引用只存在与 Prefab 中,也会出现类型丢失问题。需要手动排查并引用进 mono 防止类型被剔除。
执行
对裁剪后的包进行冒烟测试,查找并修复类型丢失的问题。
运行时,unity 会抛出类型丢失的错误,并附带一个应用 ID, 通过 ClassIDRefrence 查找,获知对应的类型。
反射引用
测试下来并未出现有相关类型报错的问题,说明代码中没有通过这种方法对类型进行引用。
资源 ab 包
出现一些 Prefab 引用类型丢失的情况,新增 link.xml 放置在 Assets 下,指导 UnityLinker 的剔除保留。1
2
3
4
5
6
7
8
9
10
11
12
13
<linker>
<assembly fullname="System">
<type fullname="System.ComponentModel.TypeConverter" preserve="all" />
</assembly>
<assembly fullname="mscorlib">
<namespace fullname="System.Security.Cryptography" preserve="all"/>
</assembly>
<assembly fullname="UnityEngine">
<type fullname="UnityEngine.Flare" preserve="all"/>
<type fullname="UnityEngine.Avatar" preserve="all"/>
</assembly>
</linker>
结果
最终包体缩小 34MB
查找文档发现 unity2017 已经新增了对 IL 代码的裁剪选项,此选项开启后会使用 UnityLinker(is a version of the Mono IL Linker) 对引擎中未引用的代码进行剔除。
剔除工作是基于代码的静态分析,需要注意以下情况,并处理。
- 如果代码中使用了反射来引用,可能会出现运行时引用类型被剔除的报错。
- 项目打包中会有 prefab 资源的提前构建 ab 包,此构建过程在 UnityLinker 调用之前执行,一些类型的引用只存在与 Prefab 中,也会出现类型丢失问题。需要手动排查并引用进 mono 防止类型被剔除。
执行
对裁剪后的包进行冒烟测试,查找并修复类型丢失的问题。
运行时,unity 会抛出类型丢失的错误,并附带一个应用 ID, 通过 ClassIDRefrence 查找,获知对应的类型。
反射引用
测试下来并未出现有相关类型报错的问题,说明代码中没有通过这种方法对类型进行引用。
资源 ab 包
出现一些 Prefab 引用类型丢失的情况,新增 link.xml 放置在 Assets 下,指导 UnityLinker 的剔除保留。1
2
3
4
5
6
7
8
9
10
11
12
13
<linker>
<assembly fullname="System">
<type fullname="System.ComponentModel.TypeConverter" preserve="all" />
</assembly>
<assembly fullname="mscorlib">
<namespace fullname="System.Security.Cryptography" preserve="all"/>
</assembly>
<assembly fullname="UnityEngine">
<type fullname="UnityEngine.Flare" preserve="all"/>
<type fullname="UnityEngine.Avatar" preserve="all"/>
</assembly>
</linker>
结果
最终包体缩小 34MB
目标
项目中为了减少打包后的包体大小,针对 IL2CPP 的打包方案做包体缩小的优化
问题
IL2CPP 虽然在性能上比 mono 有优势,但是当代码量增多时,包体会增大
研究
2015 年的一篇帖子有提到 IL2CPP 在打包时会将未使用的属性打包进 IL 中,作者测评下来发现修改裁剪工具,剔除不需要的属性能减少 6% 的 IL2Cpp 大小。
原帖地址
在 unity2017 版本中,并没有作者所提到的 UnusedByteCodeStripper2.exe 工具,推测 unity 可能在后续版本更新中做了优化。
测试 Attribute 的优化
新建空的项目工程,创建 test.cs , 对其中的 test 字段使用属性元数据。 选择 IL2Cpp 打包方案打包 apk 包,使用 IL2Cppdumper ,反编译查看包体中的 libil2cpp.so , 对比查看使用了属性以及未使用属性的打包结果。
未使用属性的 attribute 在反编译结果中未找到对应的声明
Managed bytecode stripping with IL2CPP
查找文档发现 unity2017 已经新增了对 IL 代码的裁剪选项,此选项开启后会使用 UnityLinker(is a version of the Mono IL Linker) 对引擎中未引用的代码进行剔除。
剔除工作是基于代码的静态分析,需要注意以下情况,并处理。
- 如果代码中使用了反射来引用,可能会出现运行时引用类型被剔除的报错。
- 项目打包中会有 prefab 资源的提前构建 ab 包,此构建过程在 UnityLinker 调用之前执行,一些类型的引用只存在与 Prefab 中,也会出现类型丢失问题。需要手动排查并引用进 mono 防止类型被剔除。
执行
对裁剪后的包进行冒烟测试,查找并修复类型丢失的问题。
运行时,unity 会抛出类型丢失的错误,并附带一个应用 ID, 通过 ClassIDRefrence 查找,获知对应的类型。
反射引用
测试下来并未出现有相关类型报错的问题,说明代码中没有通过这种方法对类型进行引用。
资源 ab 包
出现一些 Prefab 引用类型丢失的情况,新增 link.xml 放置在 Assets 下,指导 UnityLinker 的剔除保留。1
2
3
4
5
6
7
8
9
10
11
12
13
<linker>
<assembly fullname="System">
<type fullname="System.ComponentModel.TypeConverter" preserve="all" />
</assembly>
<assembly fullname="mscorlib">
<namespace fullname="System.Security.Cryptography" preserve="all"/>
</assembly>
<assembly fullname="UnityEngine">
<type fullname="UnityEngine.Flare" preserve="all"/>
<type fullname="UnityEngine.Avatar" preserve="all"/>
</assembly>
</linker>
结果
最终包体缩小 34MB
目标
项目中为了减少打包后的包体大小,针对 IL2CPP 的打包方案做包体缩小的优化
问题
IL2CPP 虽然在性能上比 mono 有优势,但是当代码量增多时,包体会增大
研究
2015 年的一篇帖子有提到 IL2CPP 在打包时会将未使用的属性打包进 IL 中,作者测评下来发现修改裁剪工具,剔除不需要的属性能减少 6% 的 IL2Cpp 大小。
原帖地址
在 unity2017 版本中,并没有作者所提到的 UnusedByteCodeStripper2.exe 工具,推测 unity 可能在后续版本更新中做了优化。
测试 Attribute 的优化
新建空的项目工程,创建 test.cs , 对其中的 test 字段使用属性元数据。 选择 IL2Cpp 打包方案打包 apk 包,使用 IL2Cppdumper ,反编译查看包体中的 libil2cpp.so , 对比查看使用了属性以及未使用属性的打包结果。
未使用属性的 attribute 在反编译结果中未找到对应的声明
Managed bytecode stripping with IL2CPP
查找文档发现 unity2017 已经新增了对 IL 代码的裁剪选项,此选项开启后会使用 UnityLinker(is a version of the Mono IL Linker) 对引擎中未引用的代码进行剔除。
剔除工作是基于代码的静态分析,需要注意以下情况,并处理。
- 如果代码中使用了反射来引用,可能会出现运行时引用类型被剔除的报错。
- 项目打包中会有 prefab 资源的提前构建 ab 包,此构建过程在 UnityLinker 调用之前执行,一些类型的引用只存在与 Prefab 中,也会出现类型丢失问题。需要手动排查并引用进 mono 防止类型被剔除。
执行
对裁剪后的包进行冒烟测试,查找并修复类型丢失的问题。
运行时,unity 会抛出类型丢失的错误,并附带一个应用 ID, 通过 ClassIDRefrence 查找,获知对应的类型。
反射引用
测试下来并未出现有相关类型报错的问题,说明代码中没有通过这种方法对类型进行引用。
资源 ab 包
出现一些 Prefab 引用类型丢失的情况,新增 link.xml 放置在 Assets 下,指导 UnityLinker 的剔除保留。1
2
3
4
5
6
7
8
9
10
11
12
13
<linker>
<assembly fullname="System">
<type fullname="System.ComponentModel.TypeConverter" preserve="all" />
</assembly>
<assembly fullname="mscorlib">
<namespace fullname="System.Security.Cryptography" preserve="all"/>
</assembly>
<assembly fullname="UnityEngine">
<type fullname="UnityEngine.Flare" preserve="all"/>
<type fullname="UnityEngine.Avatar" preserve="all"/>
</assembly>
</linker>
结果
最终包体缩小 34MB